一方水土养一方人,抽象话养抽象机器人🤣
初探聊天机器人开发,实现学习群聊记录,进行群聊天😋

🚧施工中,本页面还未完成(咕咕
🤖ChatBot的可行性
这是一个基于GPT-2模型的Chatbot,语料是经过清洗的我的某些群聊记录,下面是几则对话记录:
user:今天群友都在干嘛
chatbot:在学校卷
user:你是不是在卷
chatbot:我也在
user:你不许搞学术
chatbot:猫娘听不懂
user:你还猫娘是吧
chatbot:不知道,我还以为我是猫娘
user:你就一机器人
chatbot:我是什么臭鱼烂虾
user:你不是臭鱼烂虾
chatbot:这就去图书馆卷了
user:又卷?
chatbot:摆了一天了
==========================也会有语无伦次的部分=====================================
user:锐评一下原神
chatbot:原神怎么你了
user:你急了你急了
chatbot:你说的对,但是原神
user:这么喜欢原神?
chatbot:原神是一款自主研发的文明,在这里可以帮助你提出解决问题。游戏
user:说的什么意思
chatbot:原神我是认为,在一个喜欢的游戏时候。玩家都可以回答问题了,但
user:我是原批
chatbot:你这个是原友(由于语料是聊天记录,所以对话效果不免有些抽象🤣)
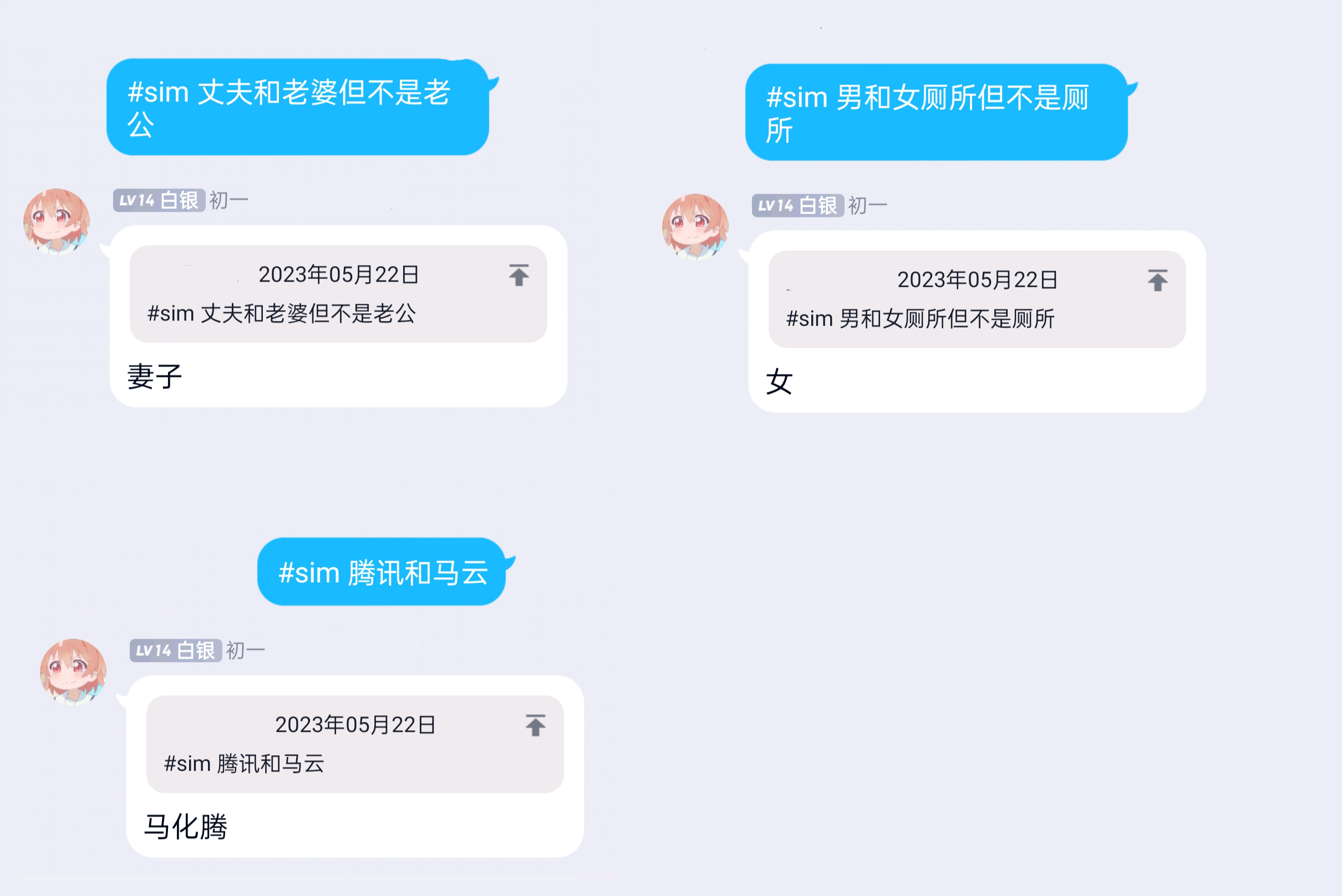
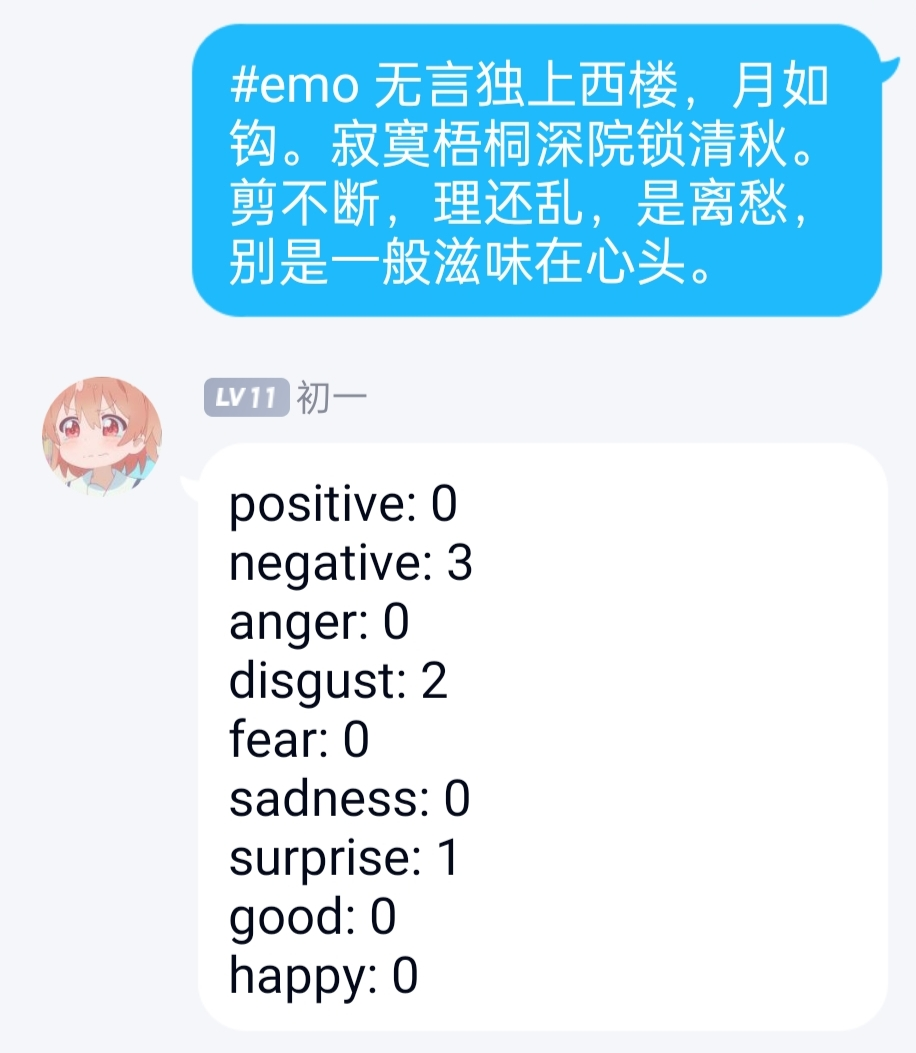
如果搭配一些QQbot的框架,即可实现群内对话(图中群友已脱敏处理,“初一”即为对话机器人):

🤖ChatBot的关键技术
1)海量文本知识表示:网络文本资源获取、机器学习方法、大规模语义计算和推理、知识表示体系、知识库构建;
2)问句解析:中文分词、词性标注、实体标注、概念类别标注、句法分析、语义分析、逻辑结构标注、指代消解、关联关系标注、问句分类(简单问句还是复杂问句、实体型还是段落型还是篇章级问题)、答案类别确定;
3)答案生成与过滤:候选答案抽取、关系推演(并列关系还是递进关系还是因果关系)、吻合程度判断、噪声过滤
🥬开胃小菜–基于情感词汇的中文情感计算
情感计算是一门备受关注的人工智能研究领域,其主要目标是赋予计算机情感能力。它涵盖两个核心方面:一是计算机的情感识别能力,即能够识别人类的情感;二是计算机的情感表达能力,即能够表达自身的情感。当前,国内外的情感计算研究主要集中在图像、声音、生理信号和文本等几个方面。
迄今为止,心理学领域尚未达成普遍认可的情感分类标准。情感的分类方式多种多样,这主要源于人类情感的复杂性和多变性,以及人们对情感的认知尚未达到足够深入和全面的程度。而我们都知道的中国传统的“七情”大致分为:好,恶,乐,怒,哀,惧,欲。
这里参考了一片论文[1]的中文情感分类,首先将情感分为7大类,这是在国外比较有影响的 Ekman的6大类情感的基础上划分的。因为6大类情感中的积极情感只有“高兴"一类,刻画得不够细致,然后又在"乐"的基础上增加了“好"—类来描述喜好、喜欢类型的情感。同时这7大类情感也基本上与中国传统的"七情"说法一致,只是少了“欲”一类。这是因为在目前的语义资源中描述"欲"类的情感词汇较少,所以没有单独划分出来作为一大类。
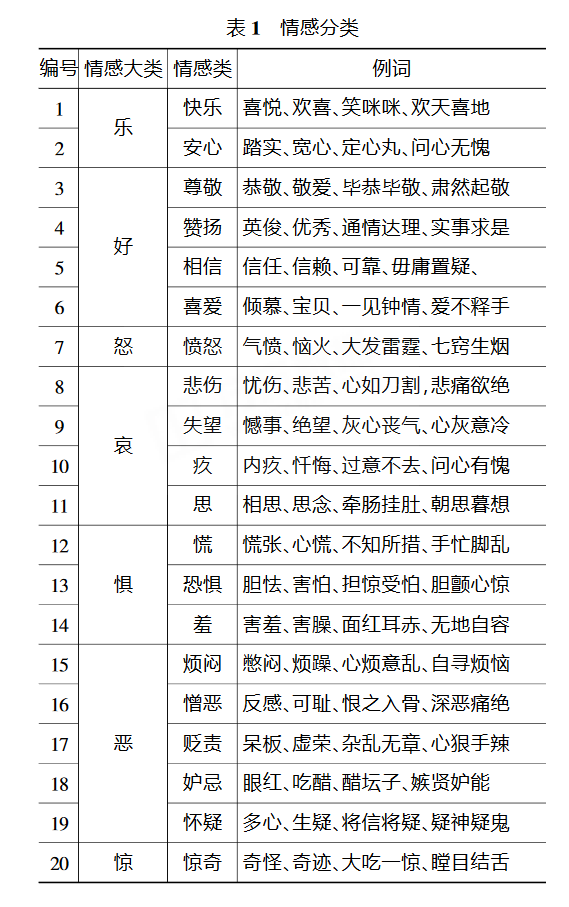
情感词汇本体通过一个三元组来描述:
其中,表示词汇的基本信息,主要包括编号、词条、对应英文、词性、录入者和版本信息。
代表词汇之间的同义关系,即表示该词汇与哪些词汇有同义的关系。
代表词汇的情感信息,是情感词汇描述框架中比较重要的一部分。
情感强度的计算首先需要两类资源,一个是标准词,另一个是大规模的语料库。标准词就是为20类情感的5个情感等级分别确定的一定量的标准词汇。通过计算词汇与每个等级的标准词汇在语料中的互信息(即共现概率)来初步确定情感强度,然后再对不合理的进行人工调整。这里采用的是点互信息(pointwise mutual information),它的计算公式如下:
其中,表示包含类情感的词汇,表示类情感的第个标准词。计算与所有类情感的标准词汇之间的互信息,选择互信息最大的那个标准词的强度作为词汇在类情感上的强度。
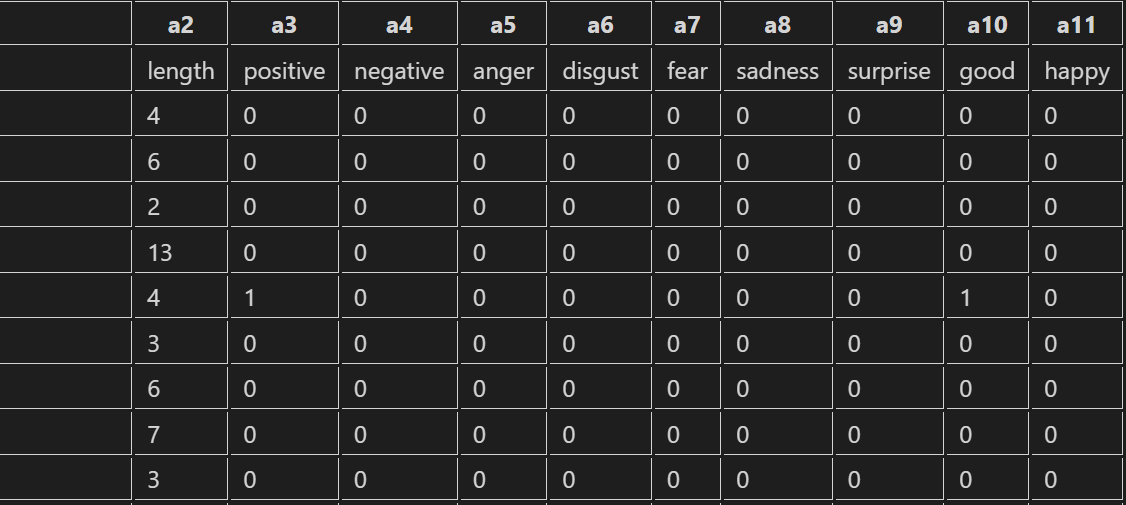
通过论文中的情感词汇本体库,我们可以编写Python程序对一段话,或者是一个语料库进行情感的计算和标注。
[1]先导入情感词汇本体的库文件
import pandas as pd
emo_path = r'D:\NLP-Project\emo_calc\data\emotion.xlsx'
emotion = pd.read_excel(path)
emotion = emotion[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
emotion.head()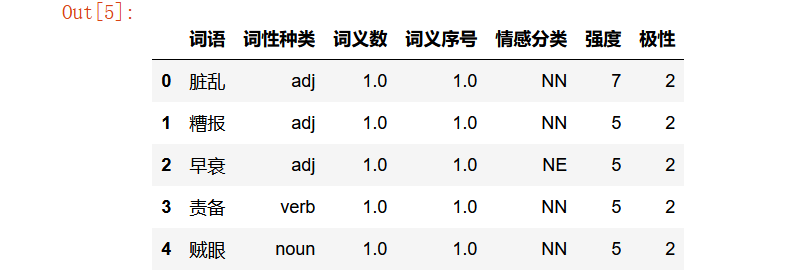
[2]整理一下情感词语
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
categories = {
'PA': Happy,
'PE': Happy,
'PD': Good,
'PH': Good,
'PG': Good,
'PB': Good,
'PK': Good,
'PC': Surprise,
'NA': Anger,
'NB': Sad,
'NJ': Sad,
'NH': Sad,
'PF': Sad,
'NI': Fear,
'NC': Fear,
'NG': Fear,
'NE': Disgust,
'ND': Disgust,
'NN': Disgust,
'NK': Disgust,
'NL': Disgust
}
for idx, row in emotion.iterrows():
category = row['情感分类']
if category in categories:
categories[category].append(row['词语'])
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust[3]情感计算的主函数
from collections import Counter
from jieba import lcut
def emotion_calculate(text):
emotions = {
'positive': Positive,
'negative': Negative,
'anger': Anger,
'disgust': Disgust,
'fear': Fear,
'sadness': Sad,
'surprise': Surprise,
'good': Good,
'happy': Happy
}
wordlist = lcut(text)
word_counts = Counter(wordlist)
emotion_info = {'length': len(wordlist)}
for emotion, wordset in emotions.items():
frequency = sum(word_counts[word] for word in wordset if word in word_counts)
emotion_info[emotion] = frequency
indexs = ['length', 'positive', 'negative', 'anger', 'disgust', 'fear', 'sadness', 'surprise', 'good', 'happy']
return pd.Series(emotion_info, index=indexs)[4]进行文章的情感计算
(1)以《紫藤萝瀑布》为例,对其进行情感计算:

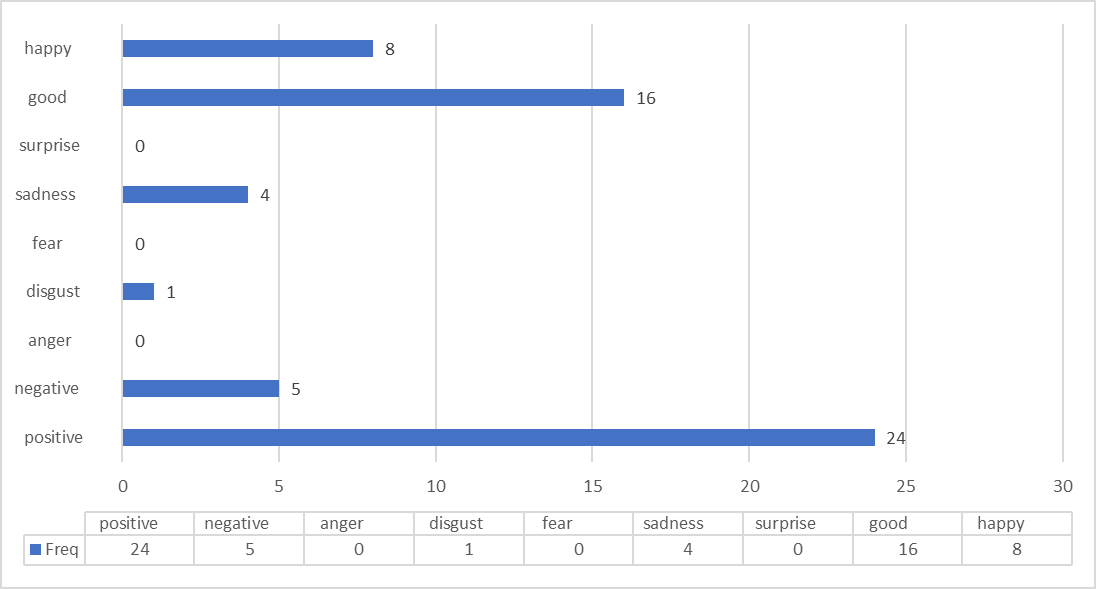
可以看出整体的情感是Positive占比大的
(2)以《在午夜,为你悲伤成河》为例,对其进行情感计算:

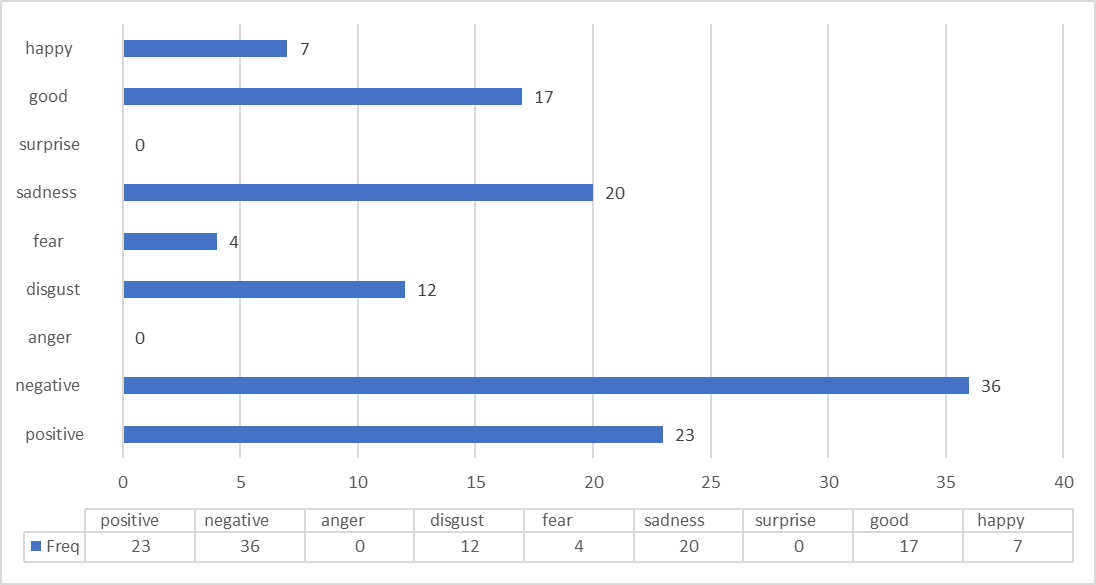
可以看出整体的情感是Negative占比大的
[5](拓展)对语料库进行批量的情感计算与标注
这里我以MongoDB储存的聊天记录为例,实现读取聊天记录文本,然后进行情感计算与标注,输出output.csv
(简化了部分预处理代码,且已做脱敏处理)
mongo.py
from pymongo import MongoClient
from pandarallel import pandarallel
import time
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
pd.set_option('max_colwidth', 100)
start = time.time()
# 创建连接
client = MongoClient('localhost', 27017)
db = client.YOUR_DB # 连接数据库
collection = db.YOUR_COLLECTION # 连接数据集合
prelist = list(collection.find())
msglist = [mesg['plain_text'] for mesg in prelist] #这里是聊天记录列表
message = pd.DataFrame(msglist, columns=['mesg'])
end = time.time()
print(end - start)
main.py
import pandas as pd
import time
import mongo
import emo_calc
# 并行计算
if __name__ == '__main__':
WORKERS = 2
pandarallel.initialize(progress_bar=True, nb_workers=WORKERS)
start = time.time()
emotion_df = mongo.message['mesg'].parallel_apply(emo_calc.emotion_caculate)
# emotion_df = mongo.message['mesg'].apply(emo_calc.emotion_caculate)
print(type(mongo.message['mesg']))
end = time.time()
print(str(end - start)+'s')
output_df = pd.concat([mongo.message, emotion_df], axis=1)
output_df.to_csv('output.csv', index=False)
print('success')
[6]搭配QQbot的框架对群聊内容在线情感分析
🥗小吃一口–基于Word2Vec的文本分析应用
当提到词嵌入或词向量时,大家会立刻联想到基于词向量进行词语拓展、文本向量化等应用。然而,实际上,词向量是一项与文本分析结合的工具或方法,可以开展许多有趣的工作。因此,本文的重点是从三个角度出发,即词嵌入的常规应用和八类用法、结合社会计算的常规词嵌入应用以及词嵌入对社会计算的概览。我们将介绍词向量(嵌入)在基本应用、技术特性以及人文社会计算领域中的使用场景,以供大家参考。(本篇参考论文:[2][3])
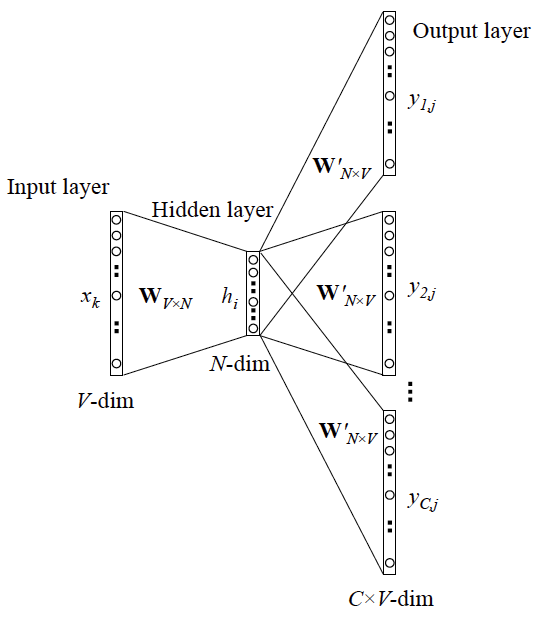
[1]Skip-gram网络结构
[2]Word2Vec数据导入
本文所用数据为腾讯人工智能实验室提供的词向量数据,使用gensim进行快速调用
from gensim.models import KeyedVectors
import time
start = time.time()
wv_from_text = KeyedVectors.load_word2vec_format('TC_Model2.bin',binary=True)
print(time.time()-start)[3]相似度计算
wv.similarity('国王','王后')
# 0.8485498 相似度高
wv.similarity('国王','王子')
# 0.81078386 相似度高
wv.similarity('钱','黑板')
# 0.19248267 相似度低
wv.similarity('沙子','土壤')
# 0.69350255 相似度适中[4]近义词分析
wv.most_similar('国王',topn=6)
# [('帝国皇帝', 0.8872873783111572), ('君主', 0.8842490911483765), ('酋长', 0.8768572211265564), ('新国王', 0.8713781833648682), ('国王陛下', 0.8662869930267334), ('亲王', 0.8610170483589172)][5]找出不合群词
wv.doesnt_match(['喜悦', '悲伤', '愤怒', '吃饭'])
# 吃饭[6]词向量加减
wv.most_similar(positive=['丈夫','老公'],negative=['妻子'])
# 老婆:0.913388 '丈夫'+'老公'-'妻子' = '老婆'[7](拓展)搭配QQbot框架实现在线词向量加减