外观
DeepSeek-R1 技术解析(上)
趣闻
2025年1月,DeepSeek-R1发布当天,英伟达股价暴跌17%。一家中国AI公司用不到OpenAI十分之一的训练成本,做出了接近甚至打平o1的推理模型——这个消息的冲击波,从硅谷一路传导到了华尔街,有人惊呼"神秘的东方力量"。
提示
论文链接:https://arxiv.org/abs/2501.12948
这篇文章想讨论的正是这个问题。我会围绕DeepSeek-R1的核心技术设计,拆解它为什么能用纯强化学习激发出推理能力、冷启动SFT起到了什么作用、以及蒸馏为什么比直接训练更有效。目标读者是对LLM有一定了解的技术爱好者——你不需要读过论文,但最好知道什么是SFT和RL。
先列出贯穿全文的七个核心问题,你可以带着它们往下读:
- 为何DeepSeek-R1-Zero能够实现"无监督推理进化"?
- 在没有明确思维链标注的情况下,纯强化学习如何促使模型自发形成复杂的推理策略?
- 模型在自我思考过程中产生的"Aha Moment",是否暗示其正在形成认知层面的元能力?
- 为何追求极致性能的Zero版本反而不适合直接产品化?推理能力的增强是否必然伴随可读性与结构的冲突?
- 仅仅基于千条人工精修数据,如何影响模型的进化路径?人类先验知识在AI进化中的杠杆效应有多大?
- 为何知识蒸馏能超越直接训练?这背后的原因是什么?
- 在大语言模型场景下,传统强化学习方法如蒙特卡洛树搜索(MCTS)为何面临严重挑战?
为了建立全局印象,先用一张表对比两个版本的核心差异:
| 模型特性 | DeepSeek-R1-Zero | DeepSeek-R1 |
|---|---|---|
| 训练范式 | 纯RL训练 | 冷启动SFT+混合RL |
| 数据依赖 | 无需人工标注 | 800k人工增强数据 |
| 输出控制 | 自由格式,阅读性差 | 结构化模板 |
| 推理特征 | 自发涌现式思考 | 结构化思维链 |
| 部署适用性 | 研究专用 | 产品级可用 |
一、DeepSeek-R1-Zero:纯RL能走多远?
很多人的直觉是:让模型学会推理,总得先给它看一些人类的推理示范吧?就像教小孩做数学题,你总得先演示几道。DeepSeek-R1-Zero的回答是:不需要。
1.1 GRPO算法设计
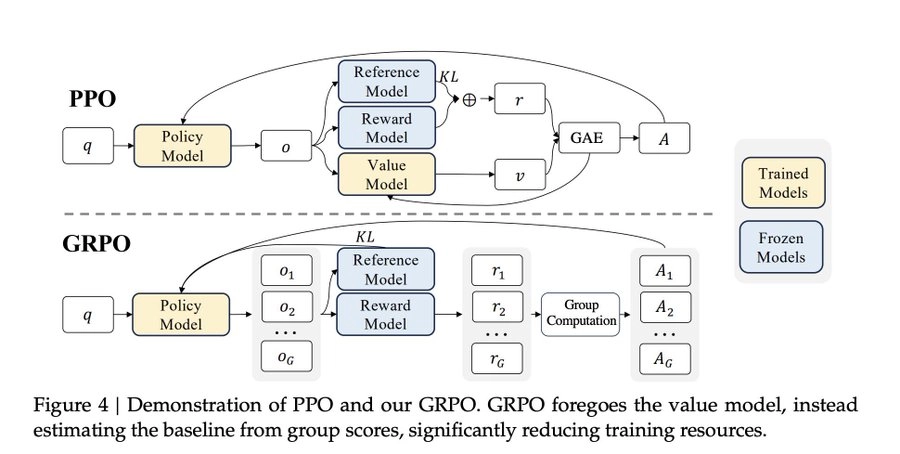
R1-Zero的核心训练算法是GRPO(Group Relative Policy Optimization)。与传统PPO不同的是,GRPO放弃了价值函数估计——这意味着不需要额外训练一个Critic模型来评估状态好坏,大幅降低了训练开销。
具体来说,GRPO做了三件事:
第一,组内相对优势评估。对每个问题采样一组回答,用组内相对排名来评估每个回答的优劣,而非依赖一个外部的价值模型来打分。目标函数如下:
第二,KL散度采用变种形式。不同于标准KL散度,论文引入了一个负对数项和常数项,在token级别施加KL约束,防止策略更新过猛导致模型"忘本":
第三,组内标准化消除奖励量纲影响。对每组内的奖励分数做Z-score标准化,使得奖励信号在不同难度的问题之间可比:
1.2 纯RL训练范式的有效性验证
训练数据极为朴素:只有数学题目和最终答案,没有中间解题步骤。通过特定的prompt模板引导模型生成思考轨迹:
Input: <Problem>x²-4x+1=0</Problem>
Output:
<Think>
步骤1:识别方程类型为二次方程
步骤2:应用求根公式x=[4±√(16-4)]/2
步骤3:计算得x=2±√3
</Think>
<Answer>
\boxed{2+\sqrt{3}}
</Answer>令人惊讶的是:即使没有人工标注的解题步骤,模型在RL过程中自主发展出了复杂的推理策略——包括自我验证、反思、以及多路径探索。这有点像AlphaGo在没有任何人类棋谱的情况下,通过自我对弈学会了围棋——只不过这次发生在了自然语言推理领域。
需要指出的是,论文并没有详细说明模型在RL初期是如何采样出推理CoT(Chain of Thought)风格输出的,只提到这是持续训练的自然结果。
训练过程中,模型不仅推理能力持续增长,甚至学会了用拟人化的语气重新审视自己的推理过程——这就是论文中著名的"Aha Moment":

这个瞬间的意义超出了benchmark涨点。它意味着模型并非仅仅在"模仿"推理格式,而是正在形成一种类似元认知的能力:意识到自己可能出错,然后主动重新思考。当然,这到底算不算真正的"认知",学界还有激烈争论,但至少从行为层面看,它确实在做这件事。
1.3 双重规则奖励机制
R1-Zero的奖励设计出奇简洁,只有两项:
- 精度奖励:对于有确定性结果的数学问题,要求模型以指定格式(例如用
\boxed{})给出最终答案,通过规则验证正确性。 - 格式奖励:强制模型将思考过程放在
<think>标签内,确保输出结构完整。
注意这里刻意避开了神经奖励模型(即用另一个模型来打分)。原因很简单:神经奖励模型容易被"reward hacking"——模型会学会伪造一些看起来合理但实际无效的推理步骤来骗高分,而不是真正提升推理能力。
二、DeepSeek-R1:从实验室到产品化
如果说R1-Zero证明了一个科学猜想——"纯RL能激发推理能力",那么R1就是在回答一个工程问题——"怎么让它能用"。
2.1 冷启动SFT
纯RL训练的早期阶段非常不稳定。模型可能生成各种混乱的输出格式,收敛缓慢。为了驯服这个"冷启动"阶段,R1团队收集了少量高质量的长思维链数据对基础模型进行微调,作为RL的初始Actor。
下表总结了R1相比Zero版本的关键改进:
| 改进维度 | Zero版本缺陷 | R1解决方案 |
|---|---|---|
| 输出结构 | 无固定格式 | 引入<reasoning_process>标准模板 |
| 语言一致性 | 中英混杂 | 新增语言一致性奖励项 |
| 认知负荷 | 冗长推理 | 强制要求<summary>摘要 |
| 模式切换 | 单一推理模式 | 增加通用能力微调 |
这里有一个值得注意的设计哲学:R1团队只用了几千条人工精修数据就完成了冷启动。这意味着人类先验知识的杠杆效应极大——不是用海量标注去"喂"模型,而是用少量高质量数据去"校准"模型进化的方向。就像给一个已经很有天赋的学生稍微指一下路,而不是从头教他。
2.2 混合奖励机制
R1的奖励设计分为两条线:
对于推理类数据(数学、代码、逻辑),延续Zero的规则奖励策略——答案对就是对,错就是错,简单可靠。
对于通用数据(对话、写作等),引入偏好奖励——让模型的输出更贴近人类偏好,例如回复更自然、更有帮助性、更符合安全规范。
这种"推理走规则、通用走偏好"的双轨制,是R1能够在保持强推理能力的同时还能正常聊天的关键。
三、蒸馏:小模型的"抄近道"?
R1的蒸馏策略很简洁:纯SFT蒸馏,不包含RL阶段。也就是说,直接用R1生成的推理数据去微调小模型,不做第二轮强化学习。
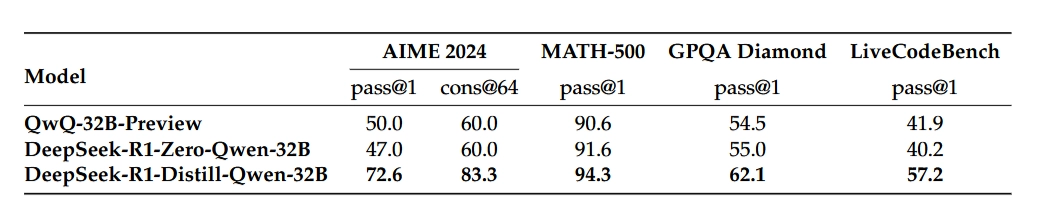
实验结果指向两个结论:
第一,同规模下,用R1蒸馏出来的小模型,效果明显优于直接在同样数据上纯RL训练出来的小模型。这有点反直觉——为什么"学别人的答案"比"自己探索"效果更好?一个合理的解释是:R1生成的推理数据质量远高于小模型自己在RL初期随机探索产生的轨迹,相当于小模型站在了巨人的肩膀上,跳过了最艰难的冷启动阶段。
第二,蒸馏虽然经济高效,但有天花板。小模型通过蒸馏可以达到甚至超越同规模模型的上限,但它无法超越为其提供数据的"老师"。想要突破智能边界,仍然需要更强大的基础模型和大规模强化学习。换句话说,蒸馏是"降本增效"的手段,不是"弯道超车"的魔法。
四、那些失败的尝试
论文中坦诚地记录了两种失败路径,这种"失败分析"在AI论文中相对少见,非常有价值。
4.1 过程奖励模型(PRM)
团队尝试过用过程奖励模型来对推理的每一步打分,结果遇到了两个棘手问题:
- 步骤划分模糊:自然语言是连续的,推理步骤的边界天然不清晰。什么算一步?"考虑使用二次公式"算一步吗?还是"代入a=1, b=-4, c=1"才算?这种模糊性让PRM的训练数据标注就无从下手。
- Reward Hacking:模型学会了伪造看起来合理但逻辑不通的步骤来获取高分。
4.2 蒙特卡洛树搜索(MCTS)
MCTS在AlphaGo中取得了巨大成功,但移植到LLM推理时碰了壁:
- 搜索空间爆炸:围棋的搜索空间已经够大了,但token级别的生成空间是指数级的更大。每一步都有几万个候选token,搜索树迅速膨胀到不可控。
- 价值函数滞后:MCTS的搜索质量高度依赖价值模型的准确性,但在LLM场景下训练一个可靠的价值模型本身就是难题——因为你又回到了PRM遇到的"什么叫好的中间步骤"这个根本性问题上。
这两个失败尝试说明了同一个道理:在LLM推理领域,基于规则的整体评估(GRPO的做法)比试图精细评估每一步更可行,至少在目前阶段是这样。
五、总结
回顾一下核心脉络:
R1-Zero证明了纯RL足以激发复杂推理能力的自发涌现,无需人工标注推理步骤。代价是输出可读性差、语言混杂,不适合直接产品化。
R1在Zero的基础上引入冷启动SFT和混合奖励机制,用少量高质量数据校准进化方向,在保持推理能力的同时大幅改善了可用性和对齐性。
一个容易被忽略的亮点是:R1从未使用推理引导的提示词设计——CoT风格是模型在训练中自发探索出来的,而非通过prompt engineering硬编码的。
最后补充一点:这篇文章写于R1发布后不久,当时这个领域的变化速度几乎是"按天算"的。如果你在几个月后才读到这篇文章,有些结论可能需要结合最新进展重新审视。