外观
DeepSeek-R1 技术解析(下)
在上一篇博客的导读部分,我们提出了多个关键问题,这些问题贯穿了整个技术设计的逻辑链条。
原论文分享的训练方法和细节并不多,复现难度不小。在许多传统观点中,我们认为训练一个具备强大推理能力的语言模型,必须对每一步推导过程进行精细监督。但 DeepSeek-R1 就是个例外——它用了一种更"野"的路子。本文继续深挖 DeepSeek-R1,从不同角度理解奖励信号是如何激发推理能力的。
提示
论文链接:https://arxiv.org/abs/2501.12948
前言
提到"推理能力",很多人的第一反应是:要让 AI 学会推理,就得像老师教学生一样,把每一步思考过程都掰开揉碎了喂给模型。这个直觉很自然——毕竟我们人类学数学也是这么过来的,老师要看你解题步骤,步骤错了就算答案对也得扣分。
但 DeepSeek-R1(以下简称 R1)系列偏偏不这么干。它选择了一条更接近"自学成才"的路线,而这条路线上最让人津津乐道的,就是那个被称为"Aha Moment"的顿悟现象。
注:全文使用"R1"指代 R1 系列模型。
一、从问题导向到结果导向
在很多领域,我们习惯于"事事必查",特别是在数学问题这种需要严密逻辑推导的任务中。目前大多数 benchmark 仅关注最终答案,对 solution 并没有严格要求,现有的改良思路是加入对 CoT 的评判。正因为 CoT 在提升模型推理能力上起到了关键作用,大部分模型的训练都会通过大量思考过程引导模型形成 CoT 的范式。
这种思路天然会带来两个问题:
高昂的数据标注成本:需要大量人力对每个推理细节进行精细标注。
灵活性降低:过分约束中间过程可能让模型难以自主探索新策略。
R1-Zero 的设计核心是将数学推理任务转化为一个仅依赖最终结果的端到端(End-to-End)学习问题。说白了就是:不要求模型按照人类偏好的方式思考,也不检查每个中间步骤是否完全正确——只要最终答案正确,并且包裹在 \boxed{Answer} 里,就给予正向奖励。
这种"只看结果不看过程"的思路,有点像高考数学的填空题:中间推导写得再漂亮,答案不对就是零分;反过来,你哪怕是用"瞪眼法"看出答案的,只要答案对,分就到手了。R1-Zero 正是在这种"结果导向"的奖励机制下,被逼着自己去摸索推理路径。
二、"Aha Moment"的再度解读
在 R1-Zero 的纯 RL 训练过程中,模型有时会突然发现一种更高效的推理路径,这就是所谓的"顿悟"(Aha Moment)。这个现象在圈内引发了大量讨论,甚至有人将其类比为"模型版的灵光一现"。
我认为这种现象并非依赖提前教授的推理技巧,而是靠大量探索涌现出来的,背后有两个关键机制:
在线采样:GRPO 在每次训练迭代中,直接利用当前策略生成候选输出(例如一段 CoT 或答案)。这些候选输出五花八门,既包括正确的也可能是错误的。
拒绝采样:GRPO 对候选输出进行筛选,丢弃低质量样本,只保留那些"看起来靠谱"的。
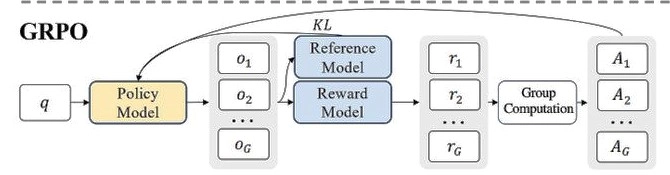
在不断采样后,模型发现了一个朴素但有效的规律:那些在输出中"多想了几步"的样本,往往能拿到更好的奖励。 于是模型学会了分配更多的"思维时间"来解决问题——简单说,就是学会了"三思而后行"。
我们目前没有一个明确的数值标准来衡量模型的推理深度。但观察发现,当模型进入"Aha Moment"时,它往往会生成更多的推理 token,这反映出模型在"花费"更多计算资源来进行复杂推理。这很像人类思考时的那种状态:有时候会陷入长时间的沉思,有时候会突然豁然开朗——这两种状态往往交替出现,而真正的突破往往发生在"多想一步"之后。
然而,这也带来了一个副作用:Overthinking。 模型有时会对简单问题也进行大量思考,甚至反复确认自己的答案——就像一个考场上不断验算一道 1+1=2 的学生。这种现象在社区里被戏称为"CPU 烧了也没想明白",虽然搞笑,但它确实是当前纯 RL 路线需要面对的实际问题。
三、SFT 与 RL
3.1 为什么 R1-Zero 选择先做 RL 而不是 SFT?
很多人会问:正常流程不是先 SFT 打底、再 RL 调优吗?R1-Zero 反过来做,主要基于三个考量:
直接从 Base 模型出发,利用 RL 进行探索,能最大程度保留 Base 模型的原始能力,不被人类偏好数据"带偏"。
高质量的 Long-CoT 数据较为稀缺,而从现有数据中硬性蒸馏出的 CoT 可能会限制模型能力的上限(指
OpenAI控诉的蒸馏问题)。R1-Zero 主要关注在数学问题上取得高分,因此只需要对最终答案进行奖励,而非对每个推理步骤都做约束。
这套逻辑本质上是"先让模型野蛮生长,再慢慢修剪"——先通过 RL 激发模型的原始推理潜能,后续再用其他手段补上可读性和通用性。
3.2 为什么最终的 R1 模型仍然需要 SFT 和偏好学习?
在 R1-Zero 训练基础上,R1 模型进一步引入了 SFT 和偏好学习,主要目的在于:
引入人类先验,提高可读性,帮助模型控制输出格式,使得生成的推理过程更符合人类的思考逻辑。
不仅限于数学推理,通用数据(如代码、谜题、摘要等)能够让模型的推理能力在其他领域得到泛化。
简单来说:
R1-Zero 是一个拥有"原始智慧"的模型,而 R1 则像是一位保留了推理锐度、同时又学会了好好说话的人类专家。
这就像一个人天生心算能力极强,但如果不学表达方式,别人根本听不懂他在说什么。SFT 和偏好学习在这里起的作用,就是把"天才的草稿"翻译成"别人能懂的论述"。
四、奖励驱动能否替代过程监督?
回到标题抛出的核心问题:奖励驱动能否完全替代过程监督?
在很多人的认知里,监督学习越精细,模型表现越好——这个直觉在大多数场景下是对的。但 R1 系列给了一个反直觉的答案。
结论是:
在特定的数学问题上,仅要求最终答案的奖励确实足以驱动模型习得复杂推理能力,过程监督在这一步骤是无效且可以去除的。换句话说,在封闭域推理任务中,"结果导向"就够了。
但在开放性任务中(如文本续写),或需要对推理过程进行精细控制的场景下,需要额外的指令微调或过程监督辅助。如果完全去除人类先验,最终可能只有 AI 模型自己能看懂 AI 模型的"黑箱推理"——两个模型聊得热火朝天,人类在旁边一脸茫然,这画面多少有些赛博朋克。
值得关注的技术演进方向: 跨任务奖励驱动、分层强化学习、记忆增强机制。
五、结语
R1-Zero 的实践证实了端到端 RL 在封闭域推理任务中的潜力:纯 RL 机制确实成功激发出了模型的"认知涌现"能力。这件事的意义不仅在于技术验证,更在于它挑战了"没有精细监督就训不出推理能力"的传统观念。
接下来的一个关键研究方向是:如何将数学推理中习得的抽象逻辑框架,高效迁移至蛋白质设计、金融建模等复杂领域。 如果这一步走通了,RL 驱动的推理能力就不只是"做题家"的玩具,而是真正能进入科研和产业场景的生产力工具。
同时,DeepSeek-R1 在 MCTS(蒙特卡洛树搜索)和 PRM(过程奖励模型)上的失败尝试也提供了宝贵的负样本,这揭示了一个深层事实:语言模型推理与传统符号推理在搜索空间、价值估计等维度具有本质差异。 把棋类 AI 的套路直接搬到语言模型上,行不通——这或许是 2024-2025 年这波推理模型浪潮给我们最重要的教训之一。