外观
具身智能学习:强化学习基础
写在前面
2025 年到 2026 年,具身智能的热度大概可以用「炸裂」来形容。Figure AI 的人形机器人进了宝马工厂,Tesla Optimus 频繁在发布会上刷存在感,国内银河通用的 Galbot 也在各种展会上搬箱子、叠衣服,春晚舞台上宇树机器人集群表演了赛博中国功夫——这个赛道明显在加速。
但真要想入行做具身智能,第一道坎就是强化学习。不管你以后是做 Sim-to-Real 迁移、做灵巧手控制、还是折腾 RLHF 对齐,RL 的基础都是绕不过去的。我以前只用Torch或者是TensorFlow做过一些 toy project,但这那些都是代码层面的积木拼接。所以我自己最近也在啃这块内容,主要针对算法方面,这篇文章就是我的学习笔记,顺带把它整理成一篇可读的东西。
本文假设你学过一点概率论和线性代数,但没碰过 RL。我会从最基本的 MDP 建模讲起,一路走到 DQN,中间穿插一些具身智能视角的解读。
特别说明
课程我主要看的是西湖大学赵世钰老师的视频以及大量的网络资料。本文偏向于笔记,而不是零基础教程。
一、MDP
1.1 Agent 与环境
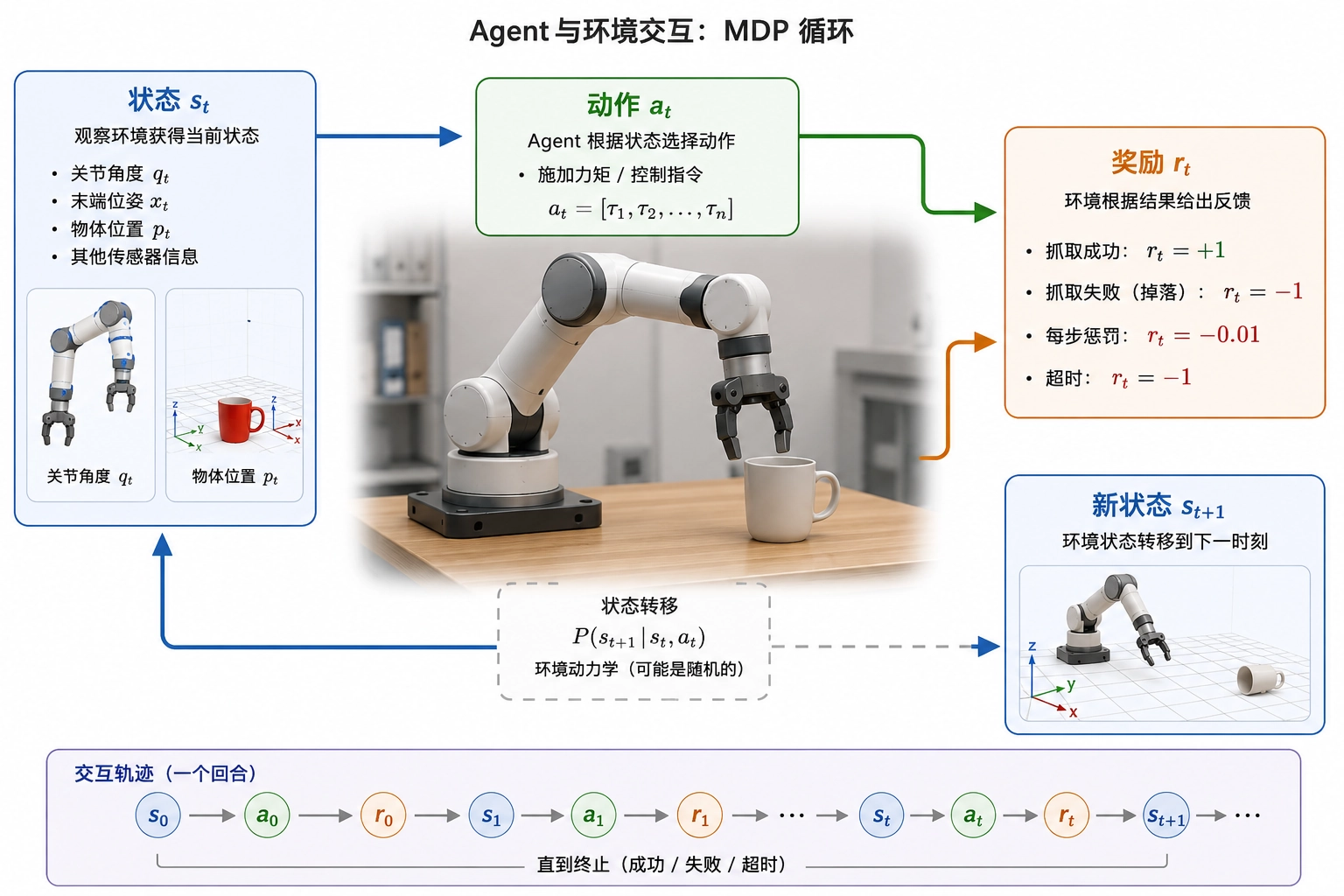
想让机器人学会一个技能,第一步不是写算法,而是把问题「翻译」成数学语言。RL 里,这个翻译框架就叫 马尔可夫决策过程(Markov Decision Process,MDP)。
想象一个机械臂正在尝试抓取桌上的杯子:它观察关节角度和物体位置(这叫状态 ),决定施加多少力矩(这叫动作 ),然后环境反馈给它抓到了还是掉了(这叫奖励 ),同时物体位置发生变化(状态转移 到 )。
这个过程在离散时间步上不断重复,形成一条轨迹:
从开始到结束(比如机械臂成功抓取或任务超时),这样一轮完整的交互叫一个回合(Episode)。
一个 MDP 问题可以用五元组来形式化定义:
其中 是状态空间, 是动作空间, 是状态转移概率矩阵, 是奖励函数, 是折扣因子。
1.2 马尔可夫性质
MDP 最核心的假设是 马尔可夫性质:未来只取决于现在,与过去无关。
真实机器人场景很少严格满足这个假设。比如导航时激光雷达被遮挡了一部分,当前的观测就不足以完整描述状态。这时候可以通过叠加历史帧来近似满足马尔可夫性质,这类问题被称为部分可观测马尔可夫决策过程(POMDP)。
顺带一提,具身智能中很多关键挑战——比如视觉遮挡、传感器噪声、环境非平稳性——本质上都是在跟马尔可夫假设做斗争。
1.3 状态转移矩阵
对于有限状态空间(小规模离散问题),状态之间的跳转关系可以用矩阵来表示:
其中 表示从状态 转移到状态 的概率,每一行之和为 1。这个矩阵是环境的一部分——如果我们能搞到它,就是有模型(Model-Based)方法;搞不到就得无模型(Model-Free)硬学。
1.4 回报:不只是眼前的奖励
智能体的目标不是最大化单步奖励,而是最大化长期累积的折扣回报(Return):
折扣因子 决定了「远见」程度:
- 接近 0:只看眼前,急功近利
- 接近 1:放眼长远,深谋远虑
可以用有效视界来直观理解:。当 时,有效视界约为 100 步——四足行走任务通常需要这么大的 ,因为每一步的稳定性都影响后续所有步态。
为什么要设计 γ?
在许多自动化任务中(例如让机器人在网格地图中导航到目标点),如果每走一步的奖励是 ,到达终点的奖励是 。
- 如果 : 无论机器人是走 10 步直线到达目标,还是在原地绕圈子走了 100 步才到达目标,其最终的累积回报都是 1。这会导致策略评估失效,智能体会产生毫无意义的冗余动作。
- 如果 : 走 10 步的回报是 ,走 100 步的回报是 。显然 。越绕远路就意味着得到目标的奖励越晚,折扣因子幂次太大了,自然会倾向于最短路径,而不是无意义的绕路。折扣因子的存在天然地为系统引入了一种「时间成本」,迫使路径规划算法去寻找最短、最高效的到达路径,这与传统启发式算法(如 A*)中最小化代价的目标是不谋而合的。
折扣因子 γ = 0.9
0.1 · 短视0.99 · 远见
65.6
72.9
81.0
90.0
100.0
59.0
65.6
72.9
81.0
90.0
53.1
59.0
65.6
72.9
81.0
47.8
53.1
59.0
65.6
72.9
43.0
47.8
53.1
59.0
65.6
可以通过滑动条调整折扣因子的大小,观察网格中每个格子的数值变化。
折扣因子越大,越看重未来的奖励,网格中数值变化越平缓;折扣因子越小,越看重眼前的奖励,网格中数值变化越剧烈。
网格中每个格子的数值为该状态的 V(s),目标格为右上角 ★
1.5 策略与价值函数
策略(Policy) 就是智能体在每个状态下选择动作的规则:
策略可以是确定性的(每个状态固定选一个动作),也可以是随机性的(按概率分布选)。具身智能中随机策略更常见,因为它能提供更好的探索能力和鲁棒性。
状态价值函数 表示从状态 出发,按照策略 行动所能获得的期望回报:
动作价值函数 则更进一步,指定了第一步做什么动作:
两者之间的关系很直观:状态价值是对所有动作价值的策略加权平均——
具身直觉
回答「站这个位置好不好」, 回答「从这个位置迈左脚好不好」。RL 算法本质上都是在想办法逼近这两个函数。
1.6 有模型 vs 无模型
RL 算法有一个根本的分岔口:
- 有模型(Model-Based):已知或学习环境模型(转移概率和奖励函数),可以做规划和「想象」。动态规划属于此类。在仿真环境(如 Isaac Sim、MuJoCo)中,有时可以利用模型加速训练。
- 无模型(Model-Free):不依赖环境模型,纯靠与环境交互采样。PPO、SAC 等算法属于此类。真实机器人上这派更实用,因为现实世界的动力学很难精确建模。
1.7 预测 vs 控制
另一个重要的区分:
- 预测:给定策略π,评估它有多好(算价值函数)
- 控制:找到最优策略π*,使得累积回报最大化
Actor-Critic 框架的妙处就在于同时做这两件事:Critic 做预测(评判当前策略),Actor 做控制(根据 Critic 的评价来改进策略)。
二、动态规划
动态规划(Dynamic Programming,DP)是 RL 的理论基石。虽然实际机器人控制中很少直接使用 DP(因为需要完整环境模型),但策略迭代和价值迭代的思想贯穿了所有后续 RL 算法——从 DQN 的 Q 值更新到 PPO 的策略优化,都能看到 DP 的影子。
2.1 动态规划三要素
DP 能解决的问题通常具备三个性质:
- 重叠子问题:子问题会被反复计算
- 最优子结构:全局最优由局部最优构成
- 无后效性:未来只取决于当前状态——这恰好就是马尔可夫性质
用一个简单例子理解 DP 的思路: 网格,机器人从左上角出发,每次只能向右或向下走,问从起点到右下角有多少条不同路径? (这题是leetcode很经典的一题)
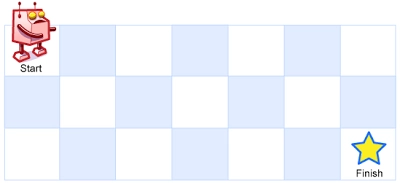
设 表示从 走到 的路径数。因为机器人只能从上方或左方到达 ,状态转移方程就是:
边界条件:,且第一行和第一列全部为 1(只有一条路可走)。第一行只向右,第一列只向下。
def solve(m, n):
f = [[1] * n] + [[1] + [0] * (n - 1) for _ in range(m - 1)]
for i in range(1, m):
for j in range(1, n):
f[i][j] = f[i - 1][j] + f[i][j - 1]
return f[m - 1][n - 1]输入 ,输出 28——这就是 DP 的自底向上思想:先解决小的子问题,逐步拼出最终答案。
2.2 贝尔曼方程:RL 的牛顿定律
把 DP 的思路套到 MDP 上,就得到了 贝尔曼方程。它描述了价值函数的递归关系——当前状态的价值等于「当前奖励」加上「未来价值的折扣期望」:
这个公式一旦展开就变成了动态规划中的状态转移方程,把整体期望拆成「当前 + 未来」两部分递归计算。
对应的动作价值形式:
2.3 贝尔曼最优方程
沿着贝尔曼方程再进一步——如果我们总是选择那个能使未来回报最大化的动作,就得到了 贝尔曼最优方程:
这两个方程是后面策略迭代和价值迭代的「指挥棒」——它们告诉我们什么是最优的,算法要做的就是逼近它们。
2.4 策略迭代
策略迭代(Policy Iteration)交替执行两步:
- 策略评估:固定当前策略 ,迭代计算 直到收敛
- 策略改进:基于 ,贪心地选择最优动作,得到新策略
这个过程像一个人做决策前反复推演——先充分评估现状,想清楚了再迈步。优点是通常需要的迭代次数少;缺点嘛,每一步评估都很贵。
2.5 价值迭代
价值迭代(Value Iteration)把评估和改进合并成一步:
基于给定的 第一步先贪心,遍历每个状态下每个动作,找出哪一个动作对应最大的 ,然后选这个动作,输出新策略矩阵,第二步进行值更新。不需要先完整评估一个策略再改进——直接往最优价值函数的方向更新。这像一个行动派,每次都是直接根据当前信息选最好的,不花太多时间反复评估。
2.6 截断策略迭代
两者的关系可以用一句话概括:策略迭代在 和 之间反复横跳直到收敛,价值迭代则是一条直线逼近 。
但在实际工程中,我们往往既想要值迭代的速度,又想要策略迭代的稳定性,一般会采用截断策略迭代。
| 算法名称 | 策略评估扫描次数 | 参数 的取值 | 策略改进时机 |
|---|---|---|---|
| 值迭代 (Value Iteration) | 只扫 1 次 | 评估 1 次后立即改进 | |
| 截断策略迭代 (Truncated Policy Iteration) | 扫 次 | ( 为超参数) | 评估 次后进行改进 |
| 策略迭代 (Policy Iteration) | 扫到收敛 | 评估完全收敛后进行改进 |
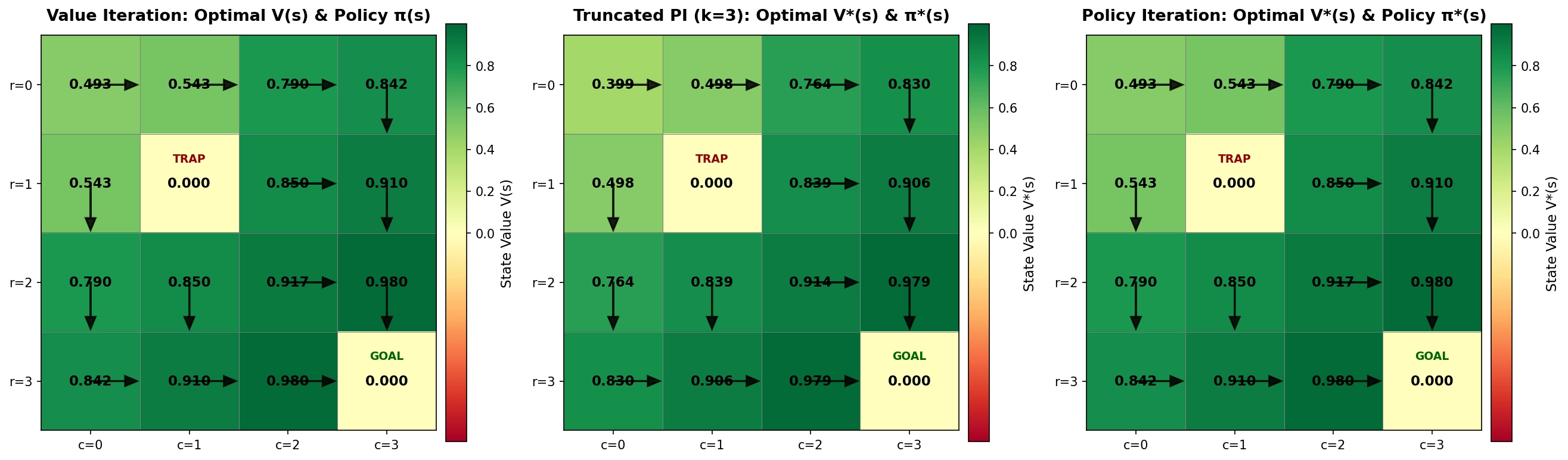
如何选择
状态空间小、模型精确时,策略迭代更高效;状态空间大、模型复杂时,价值迭代的轻量单步更新更有优势。现代 RL 实践中,价值迭代的思想(轻量更新 + 大量迭代)更深地影响了后来的算法。
三、蒙特卡洛
动态规划虽然优美,但需要知道环境模型。真实世界里,你没法提前知道「在某个关节角度下施加 2N·m 力矩后,机械臂准确到达目标位置的概率是多少」。这时候就得靠采样——蒙特卡洛(Monte Carlo,MC)方法登场。蒙特卡洛方法某种程度上就是 RL 领域的「大力出奇迹」——只要采样够多,根据大数定律,总能逼近真值。
3.1 核心思想:用采样替代积分
蒙特卡洛估计的哲学很简单:
经典例子是用随机撒点来估计 :在 正方形里随机撒点,落在内切圆内的点数比例接近 。
import random
def monte_carlo_pi(num_samples=1_000_000):
in_circle = 0
for _ in range(num_samples):
x, y = random.random(), random.random()
if x**2 + y**2 <= 1:
in_circle += 1
return 4 * in_circle / num_samplesRL 里的蒙特卡洛预测同理:完整执行一条轨迹,算出每个状态的回报,取平均作为价值估计。
提示
蒙特卡洛强化学习算法是Model-Free算法
3.2 增量式更新:边跑边记
采样全部轨迹后再平均太慢了,实际中用增量式更新:
其中 是学习率。这个公式本质上就是把估计值往目标值的方向挪一点。
3.3 首次访问 vs 每次访问
MC 预测有两种变体:
- 首次访问 MC(FVMC):每条轨迹中,每个状态只在第一次出现时(更新他)计入回报——无偏估计
- 每次访问 MC(EVMC):一条轨迹中每次访问都算一次——数据利用率更高,但偏向多次出现的状态
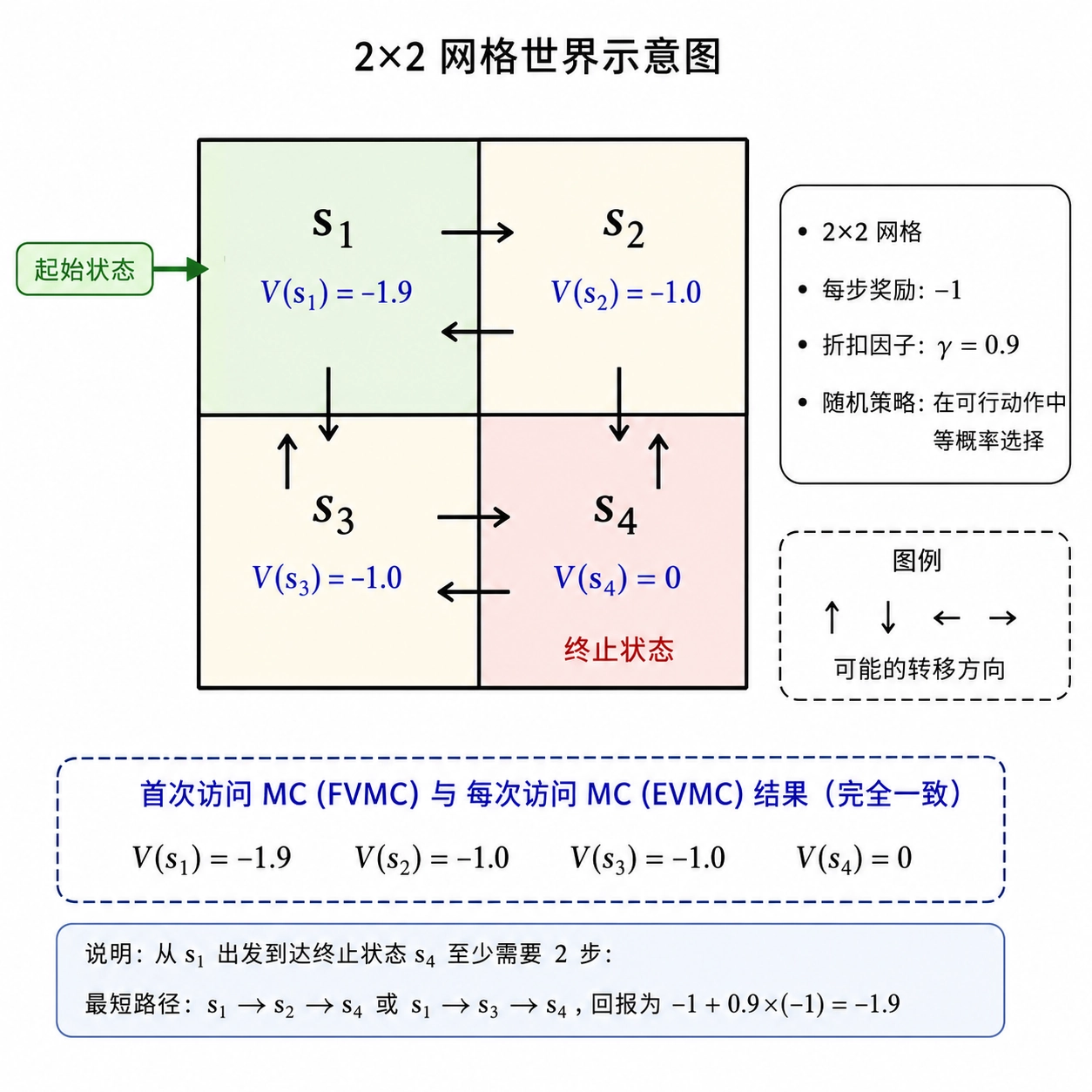
在小规模问题中两者差别不大。以一个 网格为例(起始于左上角 ,终点为右下角 ,每步奖励 ,,随机策略),两种方法的计算结果完全一致:,,。
相当于FVMC一个 episode 中,一个状态只贡献一次样本;而EVMC重复使用更多样本,且并不会引入偏差,只是方差更低。
3.4 蒙特卡洛控制:边评估边改进
把 MC 预测和策略改进交替进行,就是蒙特卡洛控制:
用一个稍复杂的例子来说明: 网格,起点 (左上),终点 (右下),每步 。在 处设一个「深坑」(额外 ), 处设一个「水洼」(额外 )。智能体只能向右或向下走。
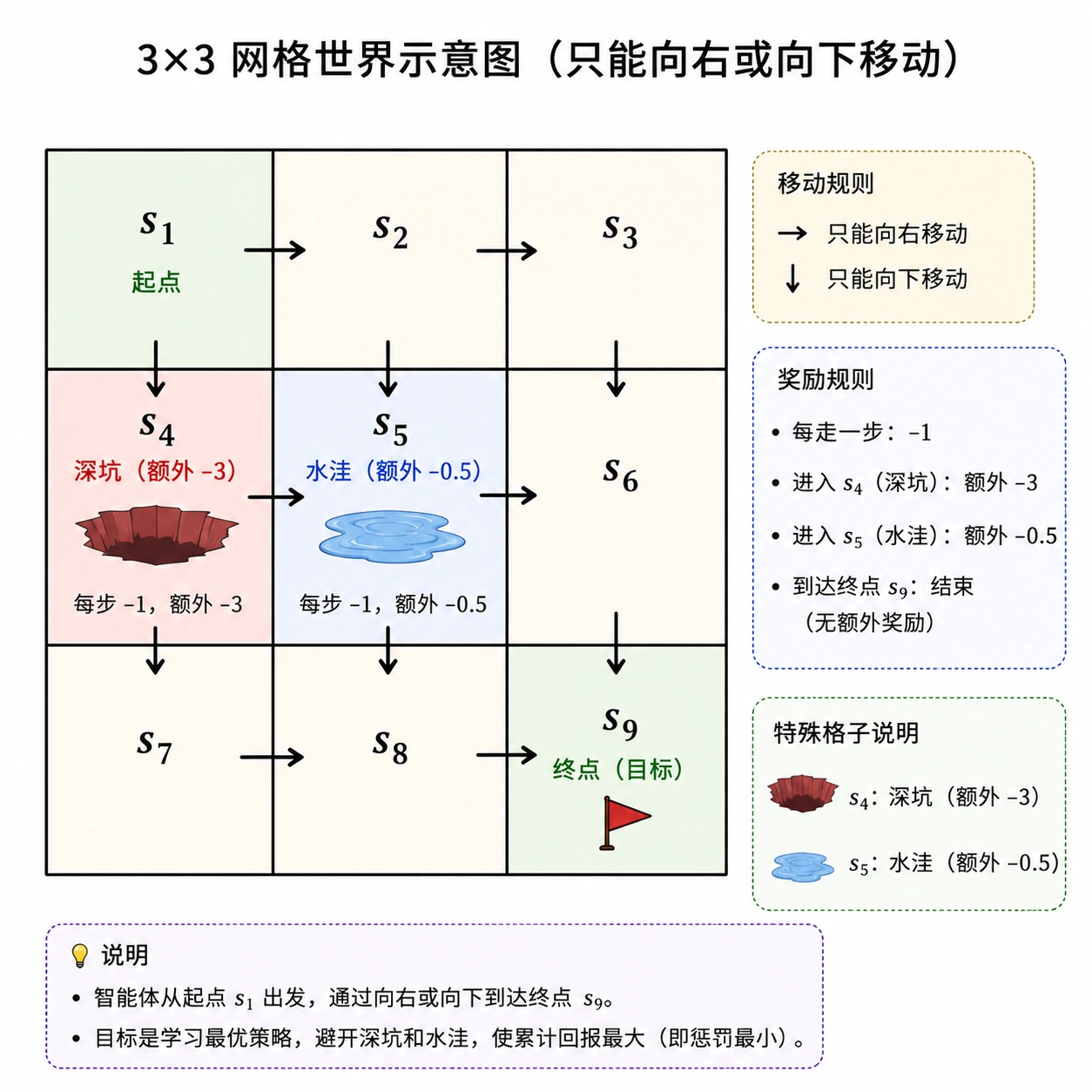
一个有意思的观察
障碍物所在位置 和 的状态价值可能反而比某些平地状态更高。这初看反直觉,但仔细想——状态价值衡量的是「从该状态出发」的未来回报期望,而不是到达该状态时受到的惩罚。从 或 出发,剩下的路程短,且不再经过障碍,所以价值并不低。反而 因为必然会经过障碍区域,价值被拖低。简单来说,Agent常常会在“绕路”还是“直接踩坑抄近路”之间做一个trade-off,在算法层面,这个取舍通常由单步行走的惩罚系数来控制;当然,调整折扣因子改变其‘目光长短’,也会间接影响这一偏好。
这其实揭示了一个 RL 的核心直觉:评估一个位置的好坏,不看你怎么到这里的,而看从这里出发你能走多远。
使用蒙特卡洛 ES(Exploring Starts)进行控制学习,智能体最终学到的最优路径是 ——完美避开了深坑和水洼。
目标 G (+100)
深坑 P (−20)
障碍墙
→ 最优策略方向
72.9↓
93.1→
95.0→
97.0→
99.0→
100.0
74.6↓
99.0↑
76.4↓
97.0↑
78.2↓
95.0↑
80.0↓
93.1↑
81.8→
83.6→
85.5→
87.4→
89.2→
91.2↑
起点 S V = 72.9 vs 深坑 P V = 93.1
🛡️ 策略: 绕长路避开
可以通过滑动条调整单步代价和折扣因子,观察起点 S 和深坑 P 的价值变化,以及策略的选择。当单步代价较低时,Agent 倾向抄近路,即使踩坑也能获得更高的总价值;当单步代价较高时,Agent 倾向绕远路避开深坑,获得更稳定的总价值。
3.5 MC 方法的优缺点
| 优点 | 缺点 |
|---|---|
| 无偏估计(FVMC) | 必须等回合结束才能更新 |
| 不需要环境模型 | 方差大,需要大量采样 |
| 概念直观,易于实现 | 不适用于无限持续的任务 |
四、时序差分
蒙特卡洛的致命伤是必须等回合结束才能更新。想想四足机器人学走路——总不能让它先摔 100 次完整走完全程再回头分析吧?时序差分(Temporal Difference,TD)方法解决了这个问题。
4.1 核心创新:用估计来更新估计
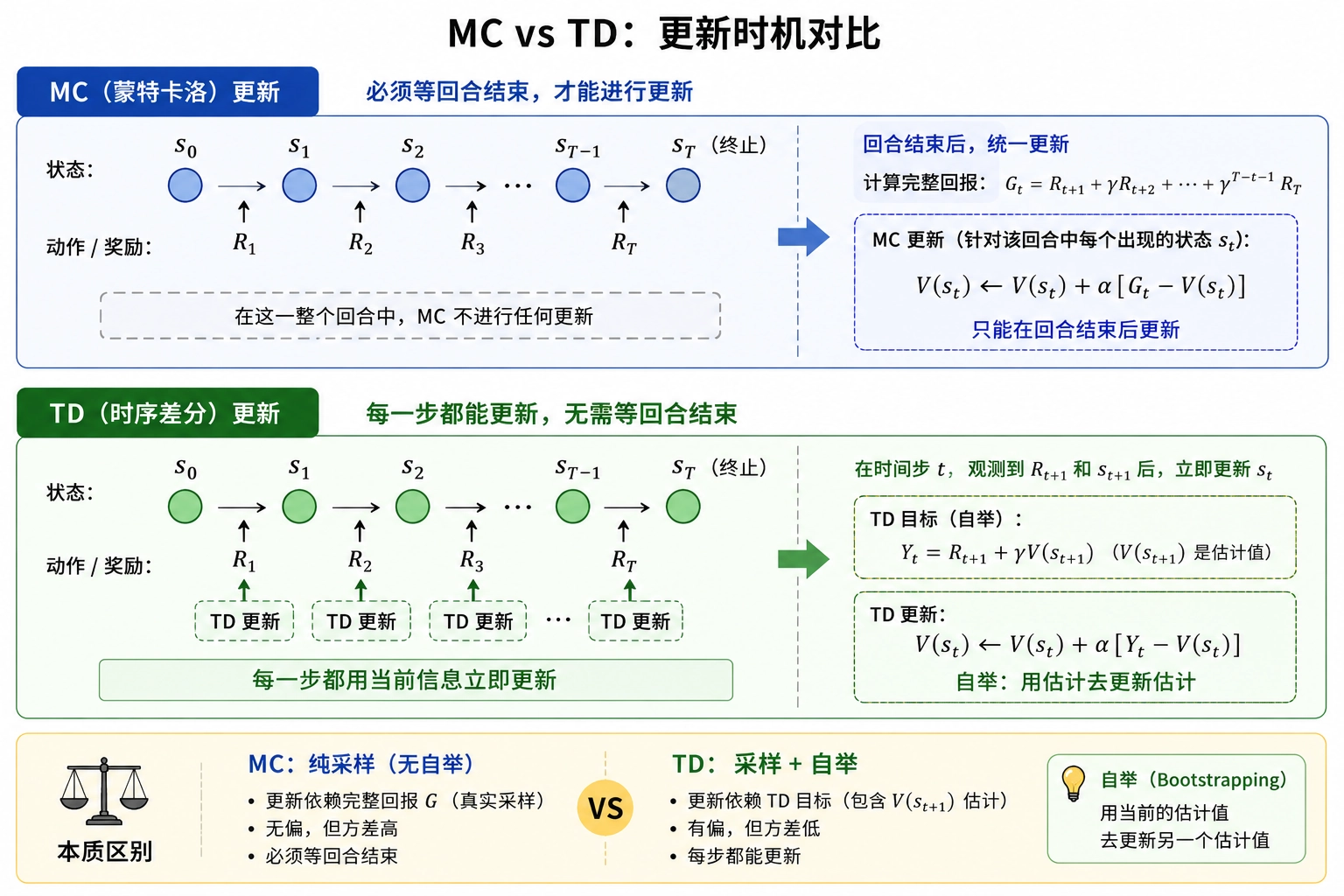
对比一下:
- MC 更新:,其中 是实际跑完的完整回报
- TD 更新:
TD 用 (称为TD 目标)替代了完整的 。关键差异在于:TD 目标里 本身也是估计值——用估计去更新估计,这叫 自举(Bootstrapping)。
两者的本质区别:
- MC:纯采样,无偏但高方差,必须等回合结束
- TD:采样 + 自举,有偏但低方差,每步都能更新
与 的差值称为 TD 误差:
这个误差量在 RL 里极其重要——它不仅衡量预测的偏离程度,在Actor-Critic 算法中还直接指导策略的更新方向。
4.2 n 步 TD:在 MC 和 TD 之间自由调节
单步 TD(TD(0))只向前看一步,蒙特卡洛(TD())看完整条路。
n 步 TD 目标:
的取值:
- :TD(0),低方差高偏差
- :MC,无偏高方差
- 中间值:在偏差和方差之间做 trade-off
4.3 Sarsa:同策略学习
Sarsa 把 TD 思想用到动作价值 上,名字来源于更新所需的五个要素::
注意这里用的是实际采取的 ——你学什么策略,就用什么策略去探索。这种「知行合一」叫同策略(On-Policy)。
为了平衡探索与利用,Sarsa 通常使用 -贪婪策略:以 概率选最优动作,以 概率随机探索。
4.4 Q-learning:异策略学习
Q-learning 的更新公式只改了一个细节,但内涵截然不同:
这里用的是 ——用一套随机策略去探索环境,不管实际走了什么动作,更新时总是假设下一步会选最优的那个。这种「眼高手低」叫异策略(Off-Policy)。
两者的系统对比:
| 维度 | Q-learning | Sarsa |
|---|---|---|
| 策略类型 | 异策略(Off-Policy) | 同策略(On-Policy) |
| 更新目标 | ||
| 收敛速度 | 较快 | 较慢 |
| 稳定性 | 可能波动 | 更稳健 |
| 适用场景 | 游戏 AI、离散决策 | 安全关键场景、自动驾驶 |
Q-learning 与 Sarsa 对比
4.5 DP、MC、TD 三者对比
把三种方法放到一起比较,各自的核心 trade-off 一目了然:
| 方法 | 需要模型 | 更新时机 | 估计方式 | 概括 |
|---|---|---|---|---|
| DP | 需要 | 每步 | 纯自举 | 有地图,按图索骥 |
| MC | 不需要 | 回合结束 | 纯采样 | 没地图,走完全程再总结 |
| TD | 不需要 | 每步 | 自举 + 采样 | 没地图,边走边猜再修正 |
DP / MC / TD 方法对比
TD 方法之所以成为现代 RL 的主流,正是因为它取了 MC 和 DP 的精华——既有无模型的灵活性,又有逐步更新的效率。
五、DQN
表格形式的 Q-learning 在状态空间大一点时就直接裂开了。想象一个 6 自由度机械臂,每个关节离散化到 100 个位置,状态空间就是 ,直接爆炸。
5.1 用神经网络替代 Q 表
DQN(Deep Q-Network)的核心思路:用一个神经网络 来近似 Q 函数,训练目标是最小化 TD 误差的平方:
其中 (非终止状态)或 (终止状态)。
看起来直接,但直接这样做会翻车,原因有二。
5.2 经验回放
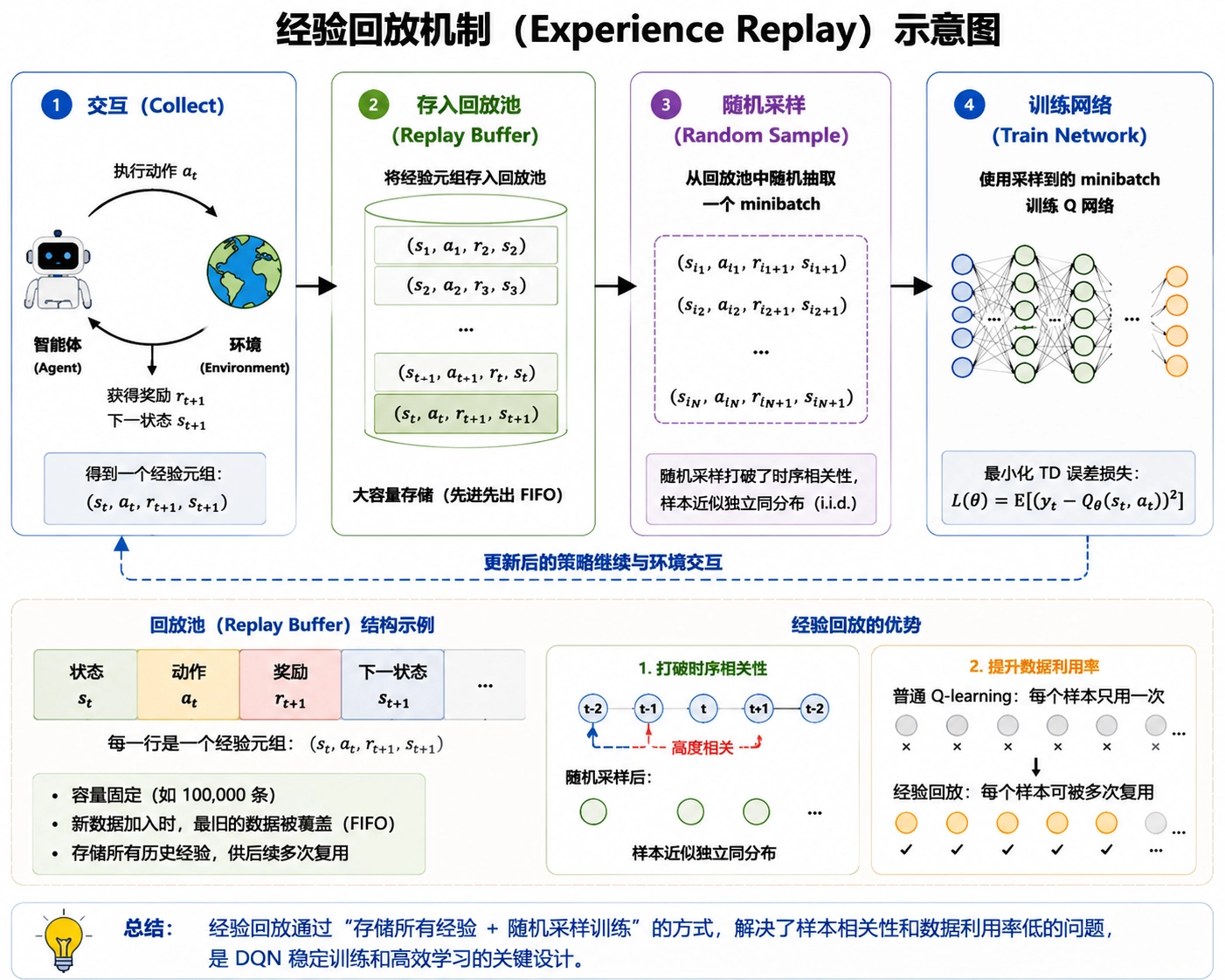
Q-learning 是每走一步拿一个样本就更新。问题在于:连续采集的样本高度相关(上一帧和下一帧几乎一样),这违反了梯度下降「独立同分布」的基本假设。而且每个样本只用一次就扔,数据利用率极低。
DQN 的解法是 经验回放(Experience Replay):把所有交互样本 存进一个回放池,训练时随机抽取 minibatch。
交互 → 存进回放池 → 随机采样 → 训练网络这个设计的妙处:一是打破了样本间的时序相关性,二是每个样本可以被多次复用,数据效率大幅提升。
5.3 目标网络
第二个问题是:目标值 里的 用的就是当前正在训练的网络参数 。意味着网络每次更新,目标也跟着变,很容易发散。
DQN 引入 目标网络 :结构与主网络相同,但参数定期从主网络复制过来,在复制周期内保持不变。
参数同步有两种方式:
- 硬更新:每 步直接把 拷给
- 软更新:, 很小(如 0.001)
软更新在 DQN 中不常用,但在 DDPG、SAC 等后续算法中广泛采用。
5.4 算法全景
DQN 的完整循环:
初始化
初始化 Q 网络 和目标网络 ,初始化经验回放池
动作选择与执行
每个时间步用 -贪婪策略选动作,执行后把样本 存进回放池
参数更新
从回放池随机采样 minibatch,计算 TD 目标(用目标网络),更新 Q 网络参数
目标同步
每隔 步,把 Q 网络参数复制给目标网络,稳定训练过程
探索衰减
随训练逐渐衰减:前期多探索,后期多利用
5.5 DQN 的局限与演进方向
DQN 是 2013/2015 年的里程碑,但远非终点。它的几个主要局限和对应的改进方向:
| 局限 | 改进 |
|---|---|
| Q 值系统性地高估 | Double DQN:用在线网络选动作,目标网络估价值 |
| 经验回放均匀采样效率低 | Prioritized Experience Replay:优先采样 TD 误差大的经验 |
| 只能处理离散动作 | DDPG、SAC 等 Actor-Critic 方法扩展到连续动作 |
| 只学期望值,丢弃分布信息 | Distributional DQN:学习回报的完整分布 |
DQN 局限与改进方向
六、写在最后
我们从 MDP 建模出发,沿着「动态规划 → 蒙特卡洛 → 时序差分 → DQN」的主线,串起了强化学习的基础知识体系。回顾一下核心脉络:
- MDP 是把任何序贯决策问题建模成数学问题的通用框架
- 贝尔曼方程 是价值函数的递归定义,贯穿所有 RL 算法
- 蒙特卡洛 用采样替代积分,是无模型 RL 的起点
- 时序差分 融合了 MC 的采样和 DP 的自举,实现了每步更新的高效学习
- DQN 用神经网络 + 经验回放 + 目标网络,把 Q-learning 推进了高维连续状态空间
对于想入行具身智能的朋友,我的建议是:不要急着跳到 PPO/SAC/Sim-to-Real 这些前沿话题。先把本文覆盖的内容吃透——理解 MDP 建模、能手推贝尔曼方程、写得出 MC 和 TD 的 Python 实现、搞清楚 DQN 为什么需要经验回放和目标网络——后面的路会顺畅很多。
下一篇计划深入策略梯度方法,从 REINFORCE 一路推到 PPO。Stay tuned.